本文参考了PTCMS官方文档和唯一度博客的原创教程,添加了一点点自己的心得。
运行环境:CentOS7+Nginx 1.19+PHP7.3+MySQL AliSQL
程序源码:PTCMS_V4.3.0(Build 20200910)
注:本教程只讲解采集规则,程序源码以及如何安装请“百度一下”。
在chrome浏览器里,按ctrl+U即可查看html文件的内容。
常用正则表达:
'[内容]' => '(.*?)',就是我们需要获取的东西
'[数字]' => '\d*',这是纯数字
'[空白]' => '\s*',这是用在换行的地方,包括换行、空格、\r \n
'[任意]' => '.*?',这就是任意字符
'[参数]' => '[^\>\<]*?',这是html代码中的参数 如alt="标题" 这样的
'[属性]' => '[^\>\<\'"]*?',这是html代码中参数的属性 对于上述例子中的alt="标题" ,可以代替标题
注:如果想要获取内容就需要在正则表达示外加括号(英文状态下的),比如(.*?) 、(\d*),括号同时只能存在一个。
注意:加粗的部分非常重要,其实我们采集最主要的表达式就是[内容]和[数字]
以https://www.txtbook.org/shuku/0_all_0_0_0_0_2_0_1.html为例讲解
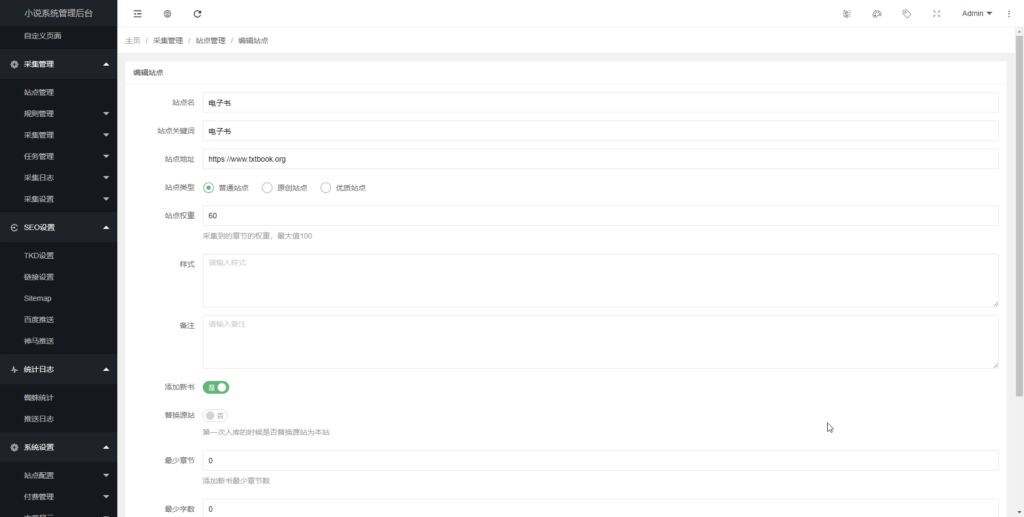
一、先找一个你想采集的网站,这里我也以唯一度博客所用的txtbook.org为例,先在站点管理那里添加站点。注意添加新书那里一定要打开。
二、采集规则详细步骤
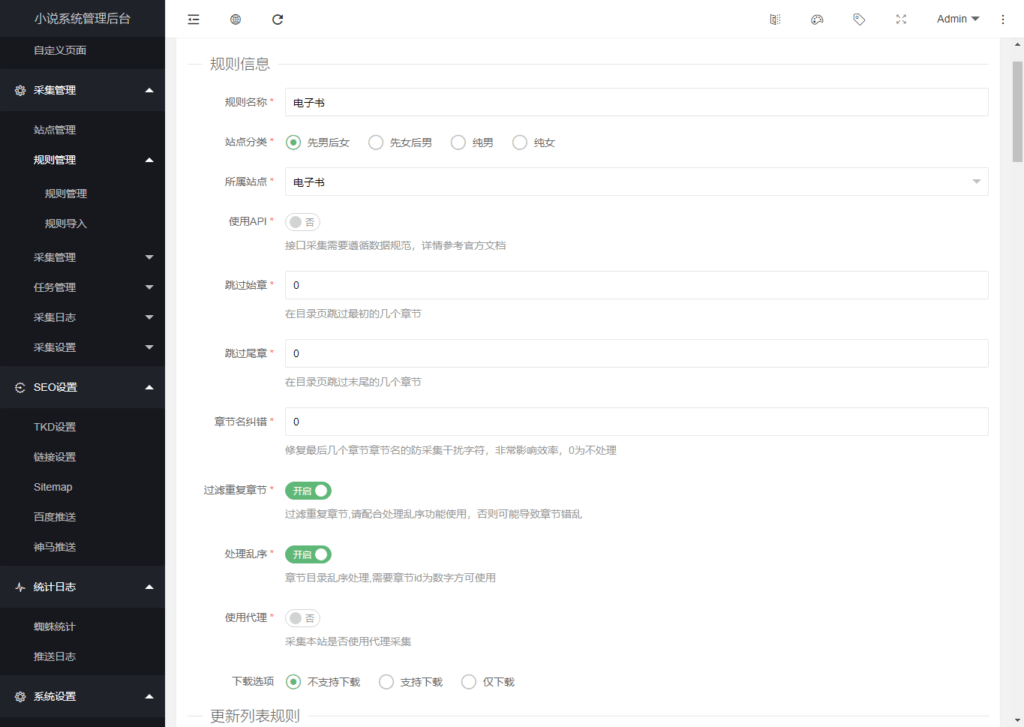
1、添加规则(规则管理-->添加);
2、规则名称根据实际情况填写;
3、所属站点选择上面添加的;其它默认就可以。
5、更新列表规则
通过分析得出如下规则


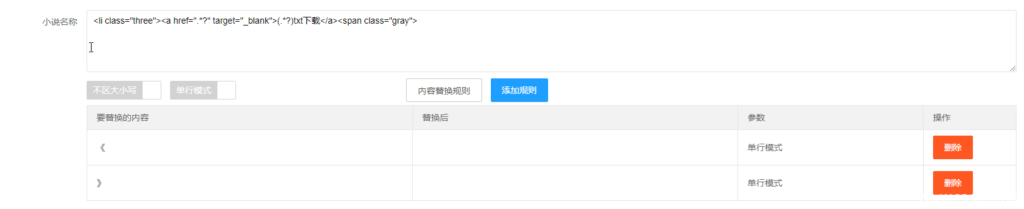
6、小说名称
根据“唯一”原则找到
分析这段代码获取我需要的数据,写规则;
方法一:
方法二:
这两种方法的区别在于方法需要替换掉《》,我用了方法二。
7、小说书号
分析代码
规则
8、信息页地址
根据URL分析,是https://www.txtbook.org/book/+书号。
在官方教程文档中有相应的参数,
[subnovelid] == 分类ID
[novelid] == 小说ID
[chapterid] == 章节ID
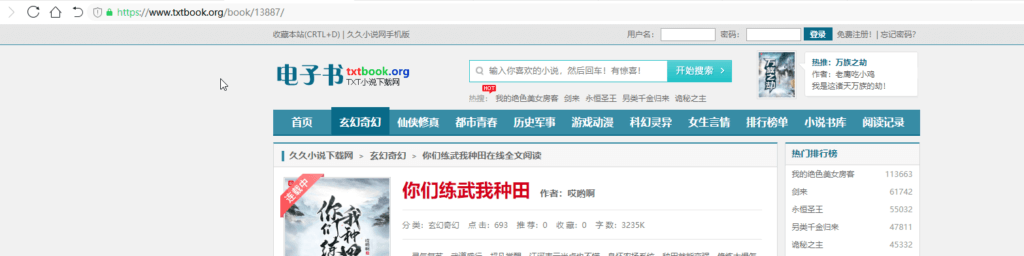

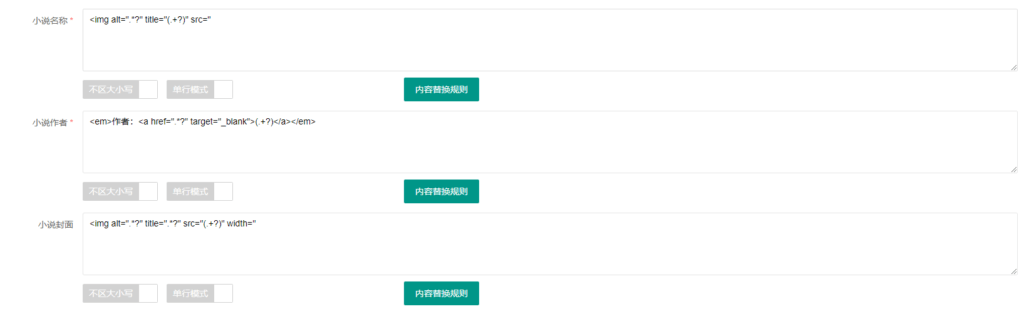
8、小说名称、小说作者、小说封面、小说分类、小说简介、小说进度
这些规则都很好找不再多写,直接看下面图片。主要说一下小说进度,也是这次为什么用这个网站作为案例讲解的原因。
在源代码查到不到连载,通过小说图片左上角的“连载中”小图标找到代码

9、通过上面学习之后,章节以及内容就很容易写了。
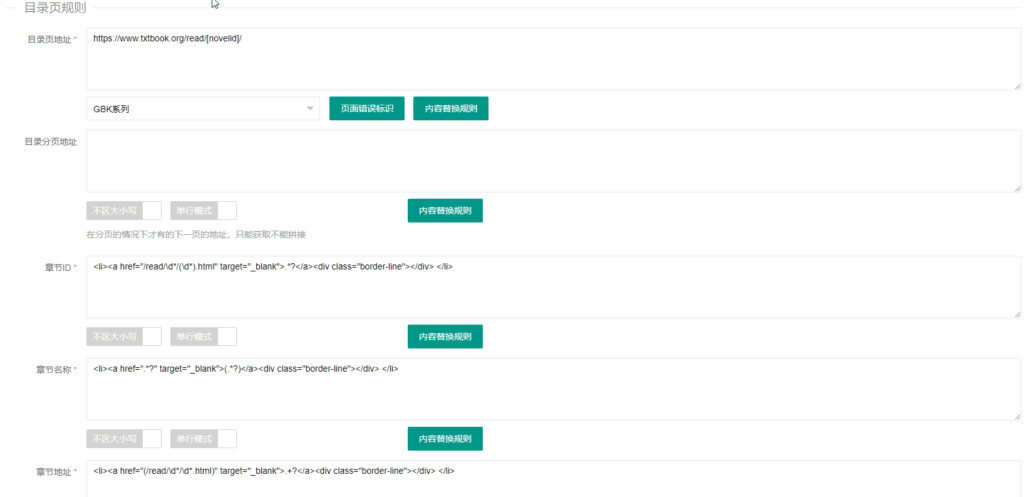
最后附上写好的采集规则:

文章评论